Par défaut lorsqu’on installe Apache depuis les dépôts de sa distribution, Apache utilise une ancienne version d’OpenSSL. A l’heure où des vulnérabilités ont été rendues publiques sur certaines versions d’OpenSSL, je vais détailler dans cet article comment compiler OpenSSL 3.0.3 et Apache 2.4.53 afin qu’il utilise les bonnes librairies sur un système CentOS 7.
Les paquets openssl étant installés nativement sur une majorité d’images de CentOS, il est nécessaire de les retirer.
sudo yum remove openssl
Mettre à jour le système et installer les dépendances nécessaires.
sudo yum update sudo yum install wget gcc make perl perl-IPC-Cmd perl-Test-Simple sudo yum install expat-devel pcre-devel apr-devel apr-util-devel
Télécharger et extraire les sources d’OpenSSL. Il sera peut-être nécessaire d’adapter le lien, sachant qu’à l’heure actuelle, la dernière version disponible d’OpenSSL est la 3.0.3.
cd /usr/src sudo wget https://www.openssl.org/source/openssl-3.0.3.tar.gz sudo tar -xvzf openssl-3.0.3.tar.gz
Compiler les sources.
cd openssl-3.0.3 sudo chmod +x ./config sudo ./config sudo make sudo make test sudo make install
Créer les liens symboliques pour pouvoir utiliser openssl.
sudo ln -s /usr/local/lib64/libssl.so.3 /usr/lib64/libssl.so.3 sudo ln -s /usr/local/lib64/libcrypto.so.3 /usr/lib64/libcrypto.so.3
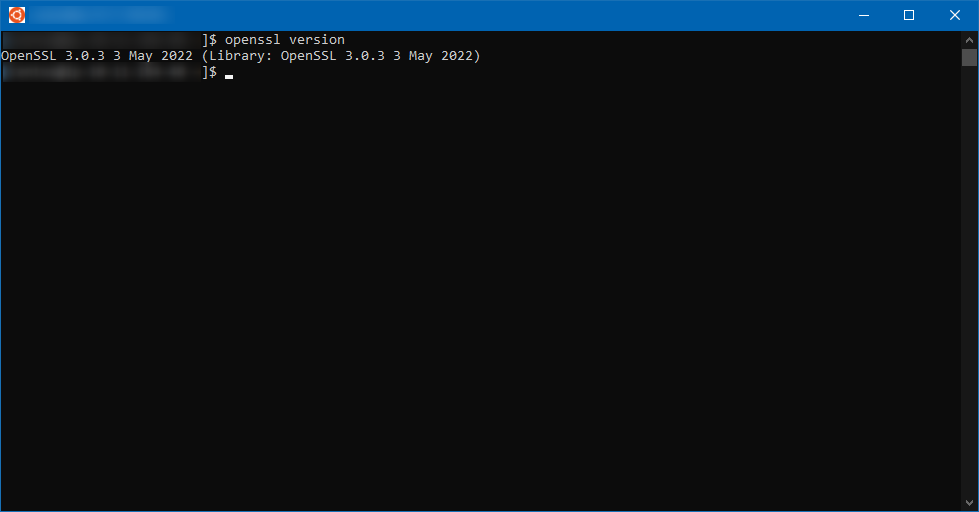
Appeler openssl pour vérifier qu’il est bien installé. La commande doit nous renvoyer le numéro de version et sa date de publication.
openssl version
Maintenant qu’OpenSSL est bien installé, il faut télécharger les sources d’Apache 2.4. Ici aussi, il pourra être nécessaire d’adapter le lien ; la dernière version disponible à date de cet article est la 2.4.53.
cd /usr/src/ sudo wget https://dlcdn.apache.org/httpd/httpd-2.4.53.tar.gz sudo tar -xzf httpd-2.4.53.tar.gz cd httpd-2.4.53
C’est ici que nous allons configurer la compilation d’Apache afin que le daemon httpd utilise notre version d’OpenSSL et non le module en version 1 généralement intégré par défaut.
sudo ./configure --with-ssl=/usr/local/ssl --enable-ssl --enable-so sudo make sudo make install
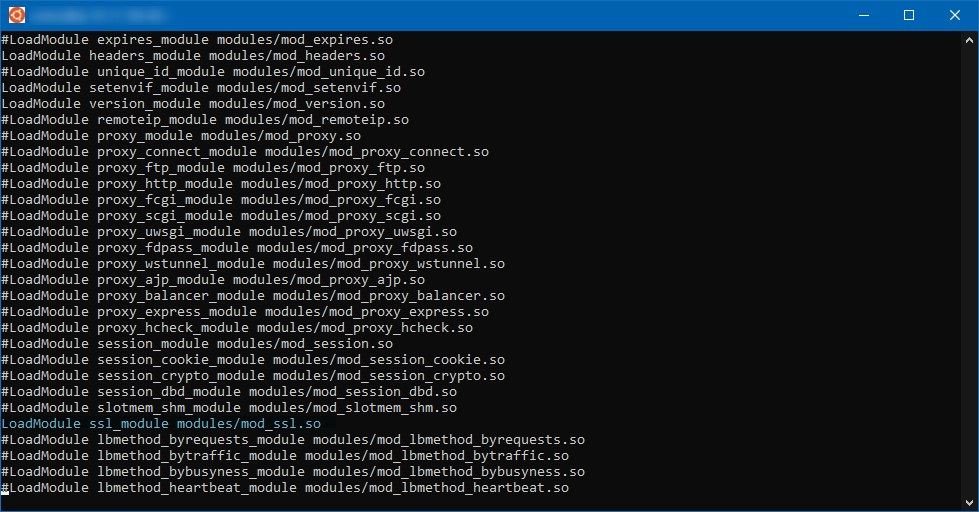
Éditer le fichier /usr/local/apache2/conf/httpd.conf avec les privilèges de superutilisateur et décommenter la ligne LoadModule ssl_module modules/mod_ssl.so.
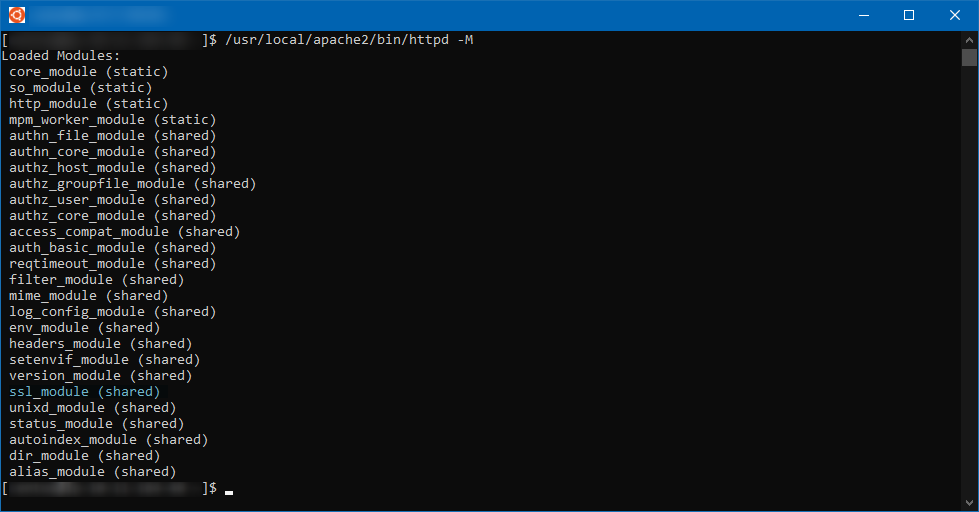
Le module doit apparaître chargé :
Démarrer le daemon httpd :
sudo /usr/local/apache2/bin/apachectl start
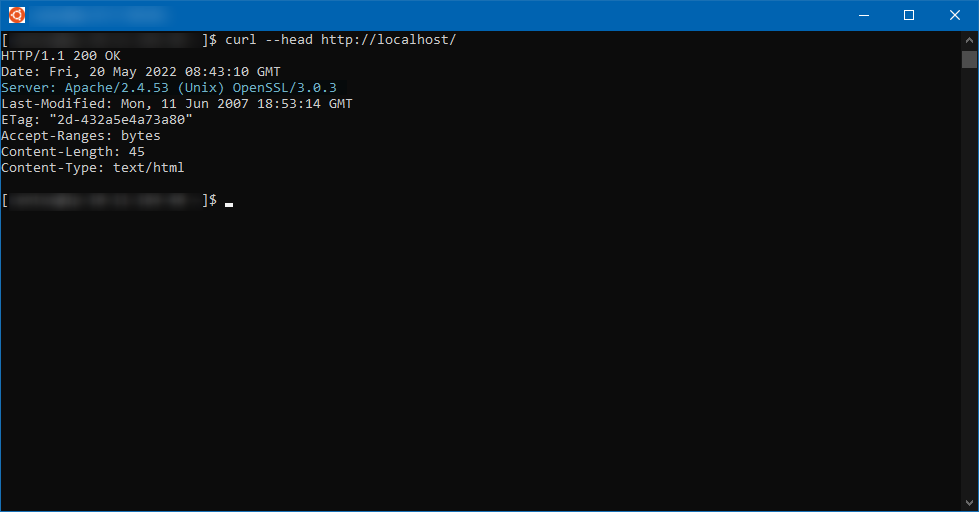
Pour vérifier la version d’OpenSSL utilisée par le serveur web, il suffit de l’interroger sur la boucle locale :
curl --head http://localhost/