PlexPy est un outil de supervision et de monitoring pour un serveur Plex. Suite à un crash de mon serveur Plex aujourd’hui – qui deviennent de plus en plus fréquents (un par semaine…) sans que je comprenne trop pourquoi – je voulais trouver un moyen d’être averti par courriel lorsque le serveur ne répond plus correctement ou lorsque le streaming est impossible. PlexPy fonctionne comme son nom l’indique avec Python et offre une interface Web. Bien qu’il soit plutôt facile à installer, je vais en détailler le processus d’installation et de configuration sur une machine Debian. A noter qu’il n’est pas nécessaire d’installer PlexPy sur le serveur Plex en question.
Tout d’abord, on créé un utilisateur qui exécutera l’application :
adduser plexpy
Je pars du principe que Python et Git sont installés sur la machine.
cd /opt/
git clone https://github.com/JonnyWong16/plexpy.git
cd plexpy
python PlexPy.py
L’idée étant que PlexPy démarre tel un service au lancement du système afin d’éviter d’avoir à laisser la console ouverte ou à passer par screen, il va falloir quelques manipulations supplémentaires ; copier-coller le contenu du fichier .service présent sur le GitHub (ou bien récupérer la version déjà renommée sur mon Google Drive) puis l’enregistrer dans /lib/systemd/system (en le renommant plexpy.service si vous avez copié/collé). Ensuite, faire en sorte que ce service démarre avec le système :
systemctl daemon-reload
systemctl enable plexpy.service
Il démarre ensuite grâce à l’instruction systemctl start plexpy.service. Il ne faudra pas oublier de s’assurer que l’utilisateur plexpy qui a été créé plus tôt soit propriétaire du répertoire de l’application :
chown -R /opt/plexpy
Le fichier .service peut se modifier si jamais l’application n’a pas été installée dans le répertoire par défaut. Pour ma part, étant le seul administrateur de la machine Plex et le seul à y avoir un accès distant, j’ai laissé le fichier de configuration dans son emplacement par défaut.
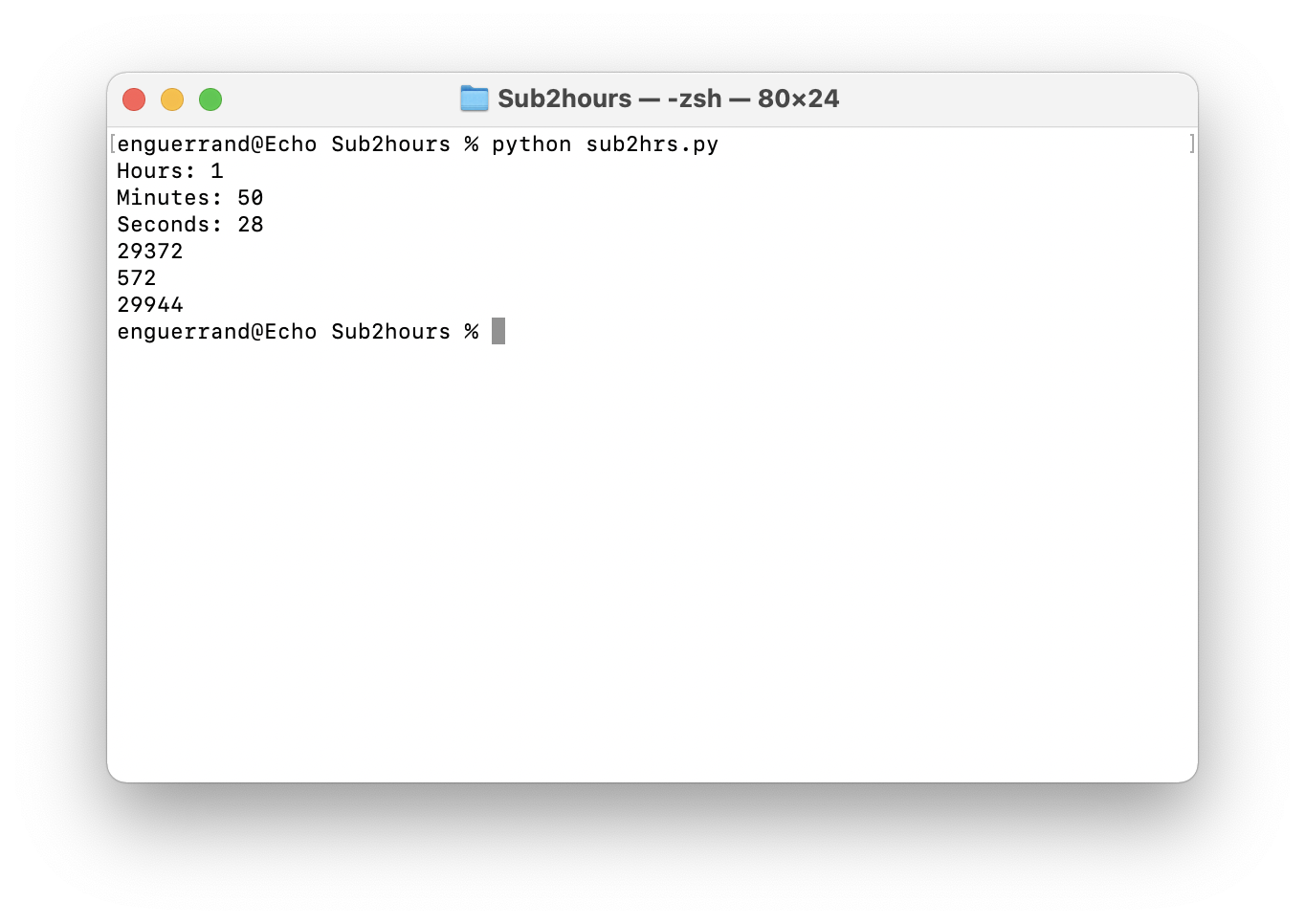
Une fois l’application exécutée, un navigateur va s’ouvrir sur http://localhost:8181. Etant connecté en SSH, c’est w3m qui s’est ouvert.
Pour plus de facilité, j’ai contrôlé la pré-configuration de l’application via un navigateur installé sur une autre machine du réseau.
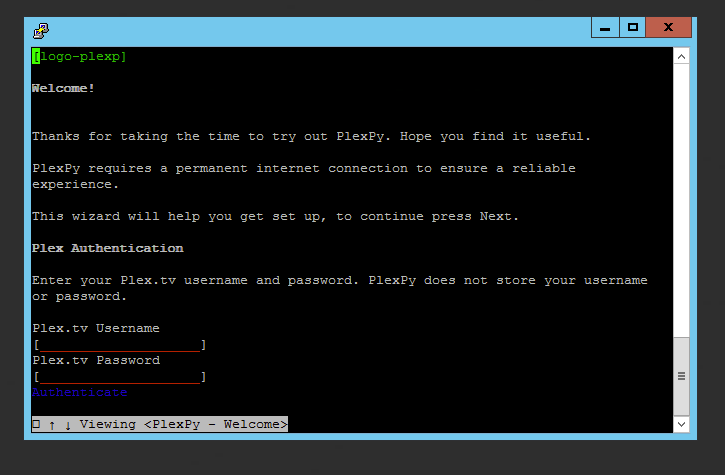
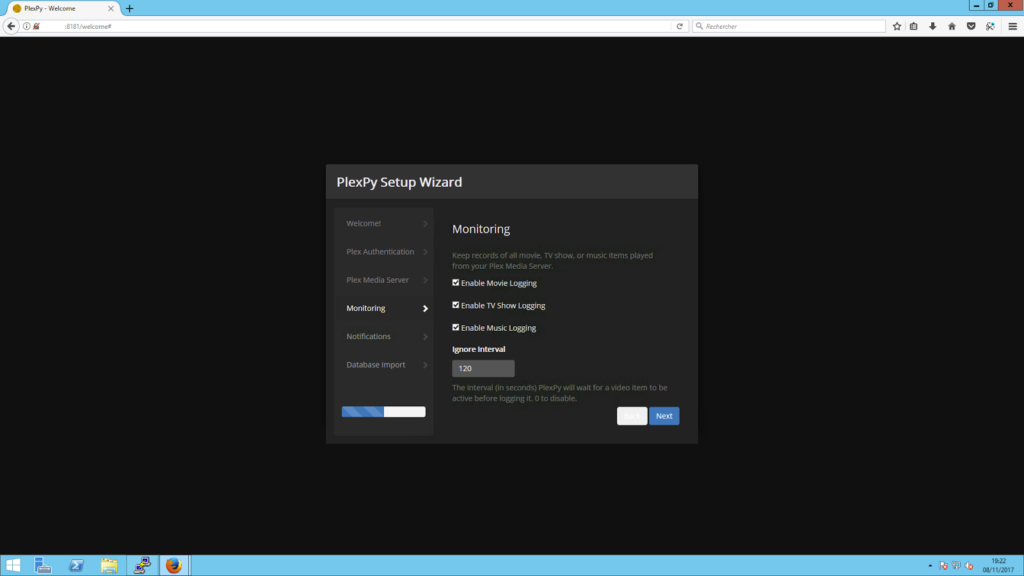
L’assistant divisé en plusieurs écrans est plutôt clair et permet de faire une configuration basique de l’outil. Par la suite, j’irai dans la configuration avancée pour modifier les notifications.
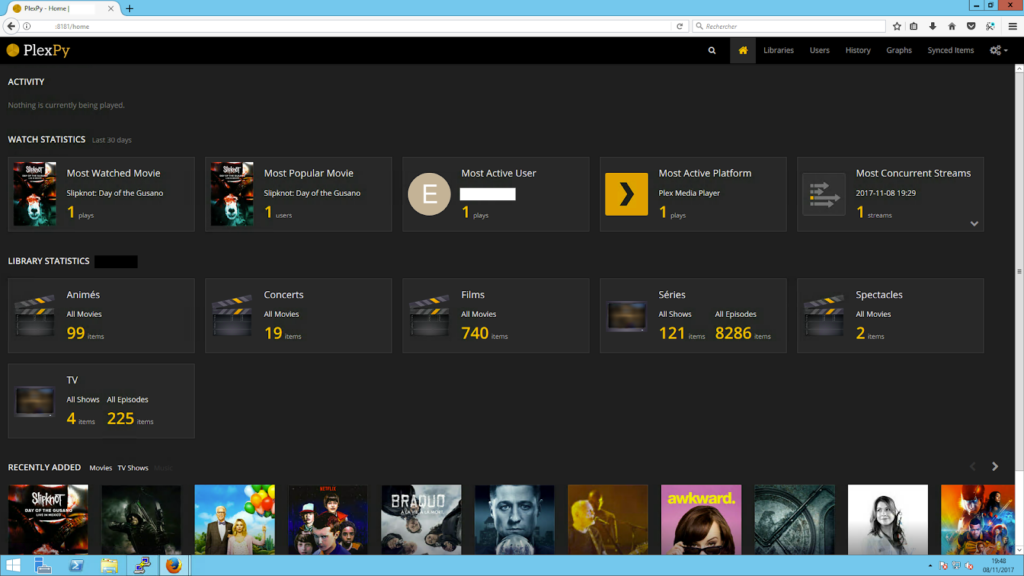
Une fois que tout est défini, on arrive sur la page d’accueil, qui présente diverses statistiques et informations par rapport au serveur Plex qui est écouté. Si l’on souhaite monitorer plusieurs serveurs Plex, alors il faut installer PlexPy autant de fois que nécessaire, sachant qu’il est possible de changer le port de l’interface web pour avoir plusieurs instances sur la même machine sans que cela ne pose problème.
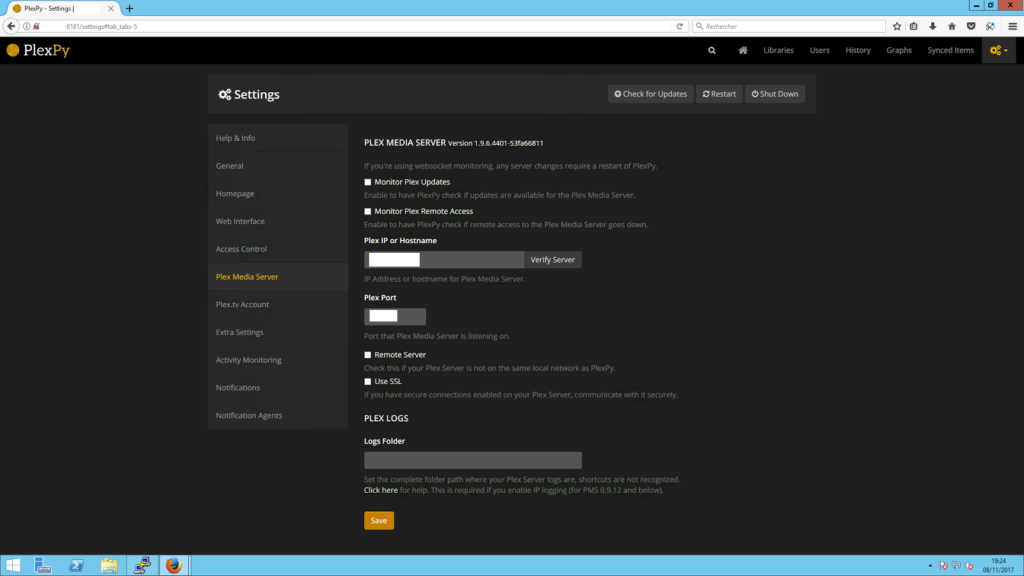
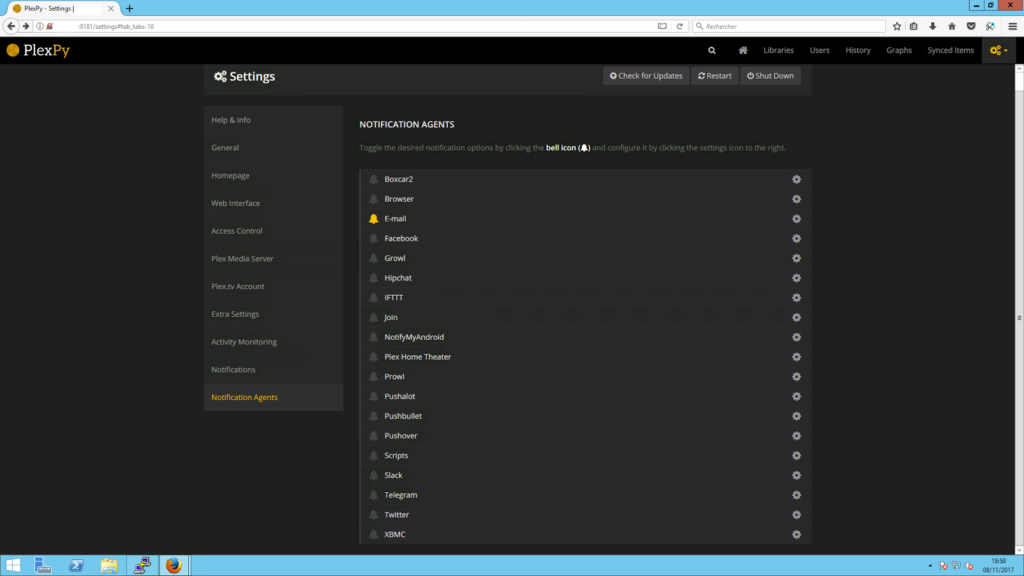
Pour configurer ce qui m’intéresse, c’est-à-dire une alerte par courriel qui m’avertit d’un éventuel dysfonctionnement de Plex, il faut aller fouiner dans la configuration avancée, qui mérite de toutes façons le détour car c’est ici qu’on configure le degré d’alerte, le moyen de contact (il est possible de recevoir des notifications par une multitude de biais autre que le courriel, notamment Twitter ou autre outils de communication comme Telegraph…) et qu’on gère toute la partie technique (base de données, taille des logs, etc.).
Le design étant proche de celui de Plex, y retrouver ses petits est aisé. Tout d’abord, je vérifie que ma configuration est bien la bonne.
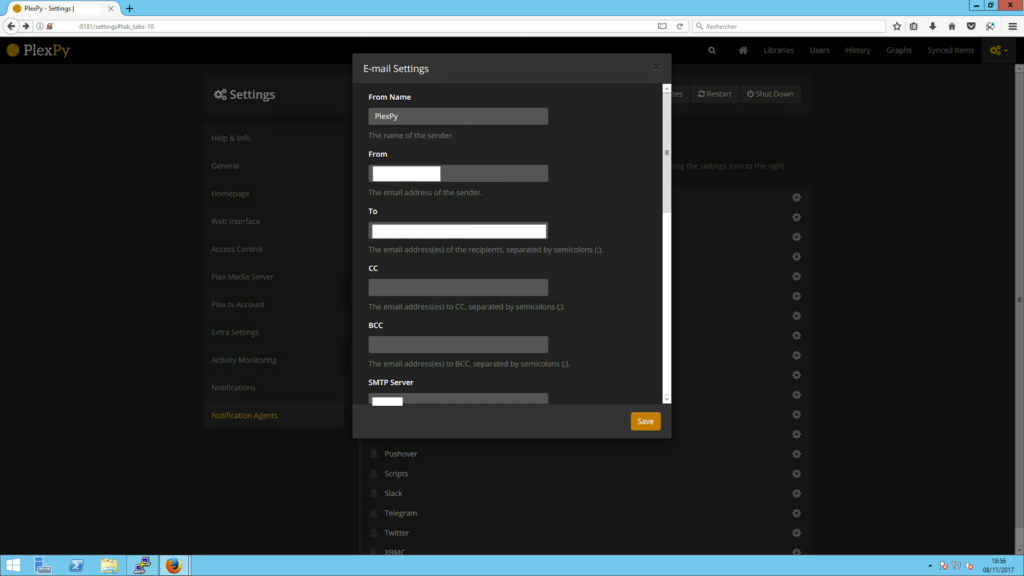
La section « Notifications » permet de paramétrer ce qui sera envoyé : titre, contenu, etc. Ce qui m’intéresse le plus cependant et là où je vais pouvoir mettre en place ce que je souhaite est dans la section « Notifications Agents ». Je choisis la ligne « E-mail » afin de la paramétrer. Il m’est donc naturellement demandé un serveur SMTP entre autres adresses émettrices et réceptrices.
Puis, une fois la configuration effectuée, un clic sur la cloche pour l’activer ; tout un panel de cases à cocher s’affiche, permettant de choisir exactement le moment où l’on souhaite être averti. J’ai donc choisi d’être averti par courriel lorsque le serveur est inaccessible et lorsqu’il revient en ligne.
J’aime ça :
J’aime chargement…