Si Microsoft s’ouvre de plus en plus vers le monde GNU/Linux, cet effort se retrouve principalement sur Windows Server 2019. Cependant, il est tout à fait possible d’installer OpenSSH sur Windows Server 2016 et ainsi d’administrer son serveur à distance en utilisant la dernière version de Powershell, ou encore de pouvoir faire du transfert de fichier via SSH comme sur un hôte GNU/Linux.
Bien que Microsoft indique que les binaires OpenSSH ne soient pas suffisamment stables pour un usage en production, je n’ai rencontré aucun dysfonctionnement pénalisant avec dans mon environnement de test et j’ai intégré OpenSSH à ma dernière révision du master. Chaque environnement étant différent, il reste important de tester avant une intégration en production.
Les sources de Powershell V7 se trouvent sur le GitHub de Powershell accessible à ce lien. Les sources d’installation d’OpenSSH pour Windows se trouvent sur ce GitHub.
L’installation de Powershell V7 se fait simplement en exécutant le setup ; cependant, l’implémentation d’OpenSSH sous Windows semble rencontrer des dysfonctionnements lorsqu’elle doit gérer des répertoires avec des espaces. Je vous conseille donc d’installer PS dans un autre répertoire que celui proposé par défaut ; dans cet exemple je l’ai installé directement à la racine du C:\.
L’installation d’OpenSSH se fait également en dézippant l’archive. Pour les mêmes raisons que précédemment, je vous conseille de déployer les binaires dans un répertoire sans espace (et de manière générale, de bannir les espaces des noms de fichiers !).
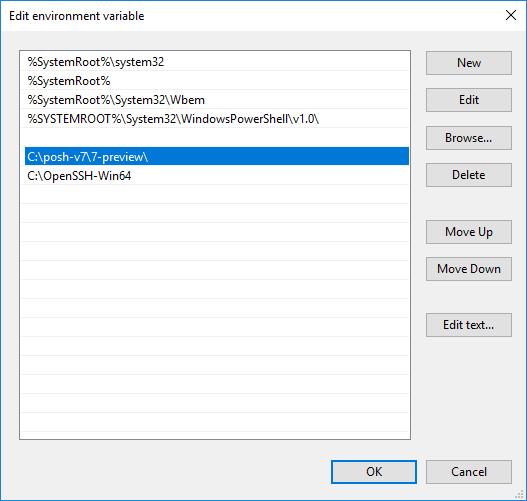
Vous pouvez désormais ajouter les deux répertoires à la variable système PATH, comme ceci :
L’installation d’OpenSSH se fait en Powershell, avec une élévation en administrateur :
cd C:\OpenSSH-Win64
.\install-sshd.ps1
Ce script va créer deux services que l’on peut retrouver dans la console. Par défaut, les services ne sont pas démarrés (c’est pourquoi je les ai intégrés à mon master, ainsi je peux les activer si il y a besoin, sans cela ils restent « dormants » sans avoir d’impact sur le système). Il faut donc les démarrer, et en fonction du besoin, activer le démarrage automatique.

Ensuite, il convient de générer une clef SSH. Toujours dans le répertoire d’OpenSSH :
ssh-keygen.exe -A
Le fichier de configuration est identique à celui que l’on peut retrouver sur un système GNU/Linux utilisant OpenSSH. Il suffit de copier le fichier sshd_config_default vers un nouveau fichier nommé sshd_config dans le répertoire C:\ProgramData\ssh et d’y appliquer les paramètres désirés et de redémarrer le service pour que les changements soient pris en compte.
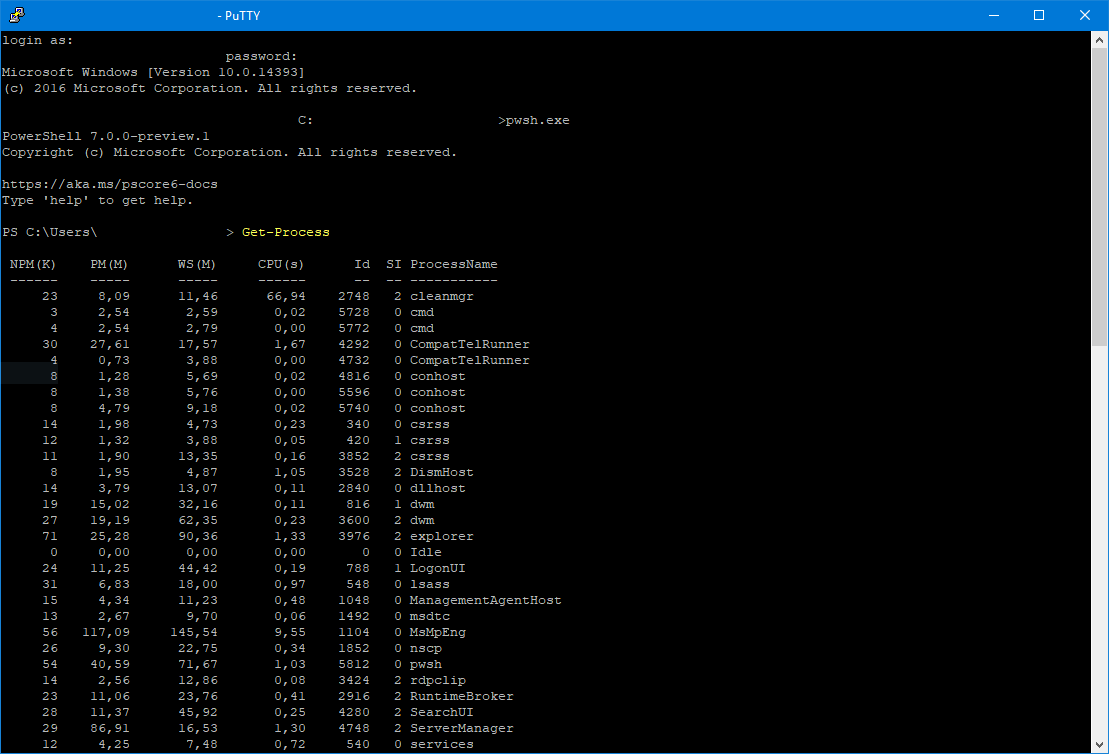
Tout est prêt. Il ne reste plus qu’à ouvrir une connexion en SSH pour tester le bon déroulement de l’installation. Une fois la connexion établie avec son login Windows usuel, il suffit d’appeler le moteur Powershell pour faire ce que l’on souhaite :
En utilisant la console, on peut tomber sur quelques bugs d’affichage si jamais la console Putty a été redimensionnée :
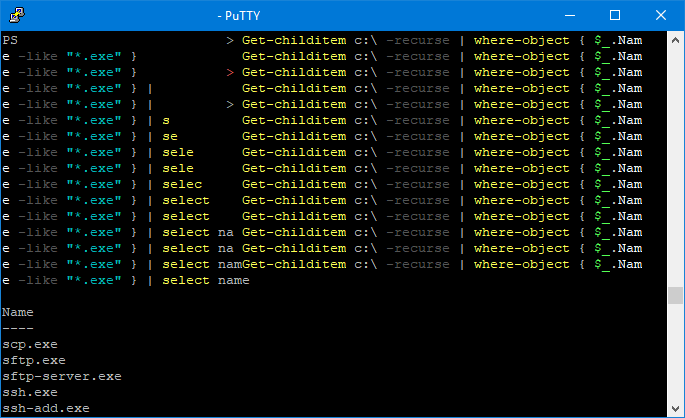
En dehors de ces petites imperfections qui montrent que ces binaires n’en sont pas encore à un véritable état de release, la connexion est stable. Je me suis pris au jeu d’effectuer quelques tâches et c’est relativement plaisant de pouvoir effectuer du Powershell à distance via SSH, WinRM étant bloqué dans mon environnement. OpenSSH permet par ailleurs de faire du transfert de fichier via SSH, grâce à WinSCP par exemple :