Si la problématique de la sauvegarde de contrôleurs de domaine et surtout de leur restauration fut un temps épineuse, ce n’est plus tellement le cas de nos jours, grâce à des avancées côté Windows et côté outils de sauvegarde.
Dans le cadre d’un contrôleur de domaine virtuel, si réaliser un snapshot avant d’installer des mises à jour Windows par exemple peut partir d’un bon sentiment, c’est la catastrophe assurée en cas de retour en arrière, toute la cohérence de l’annuaire étant remise en question puisque le DC sera incapable de comprendre pourquoi il se voit présenter des mises à jour venant du futur puisqu’il aura été restauré à un état passé comme si rien ne s’était passé depuis la création du snap. L’outil Windows Server Backup peut être un bon point de départ pour la sauvegarde d’AD ; cependant l’emplacement de stockage n’est peut-être pas toujours défini à l’avance et l’outil peut ne pas s’intégrer dans les politiques de sauvegarde de l’infrastructure générale.
Récemment, j’ai pu effectuer sur une plateforme de tests la sauvegarde et la restauration de contrôleurs de domaines virtualisés sous vSphere ESXi grâce à Veeam Backup & Replication. Dans cet article, je vais aborder les points principaux d’une telle manipulation si un contrôleur de domaine ne démarre plus (et que par conséquent, la structure de l’AD est intacte), sans oublier de rappeler qu’il est indispensable de valider sur des environnements iso ces procédures de sauvegarde et restauration, en plus d’avoir connaissance de la documentation Veeam à ce sujet (p. ex. ces deux articles : ici et là). Dans le cas où la cohérence même de l’annuaire a été remise en question
(corruption, par exemple), d’autres étapes peuvent être requises
(je pense notamment par un passage par le DSRM) mais je ne les aborderai pas dans cet article.
La plateforme de test est composée de 4 machines : 3 contrôleurs de domaine 2012 R2 et un client Windows 10, sous vSphere 6.5 et sauvegardée par Veeam Backup & Replication en version 9.5.
Tout d’abord, il est important de vérifier que le job de sauvegarde des DC ait l’option Enable Application-aware Processing d’activée.
Bien sûr, avant de s’engager dans plus de manipulations, il sera bienvenu de s’assurer que les sauvegardes ont été réalisées avec succès en temps et en heures.
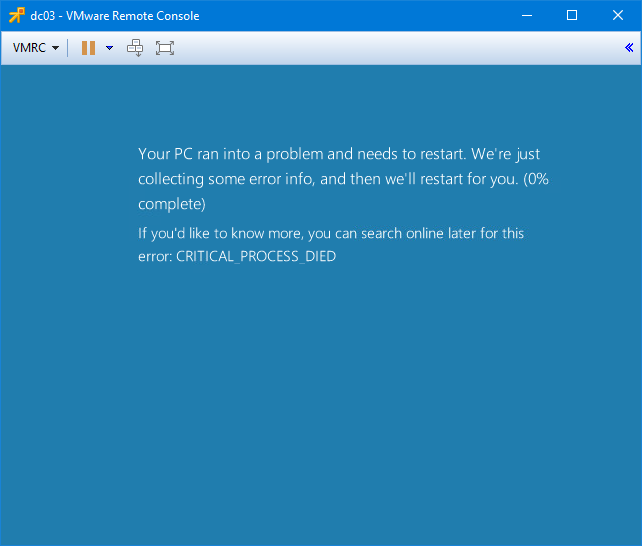
Suite à des manipulations sur dc03, j’obtiens un célèbre BSOD :
Ce DC doit donc être restauré. Dans VMware, je vais procéder à sa mise hors-tension, et à la suppression de la VM.
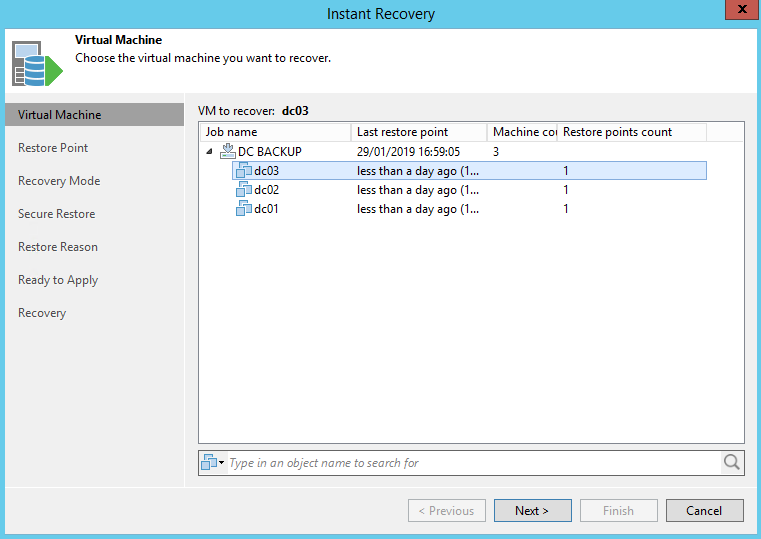
Dans Veeam, je vais procéder à la restauration de la VM, en utilisant les options Entire VM Restore puis Instant Recovery.
Je choisis de restaurer la VM to the original location, sans connecter le réseau ni directement démarrer la VM. Une fois cette opération terminée, la VM sera ajoutée dans VMware et stockée sur le pool de sauvegarde Veeam ; il faut la déplacer sur le stockage de production.
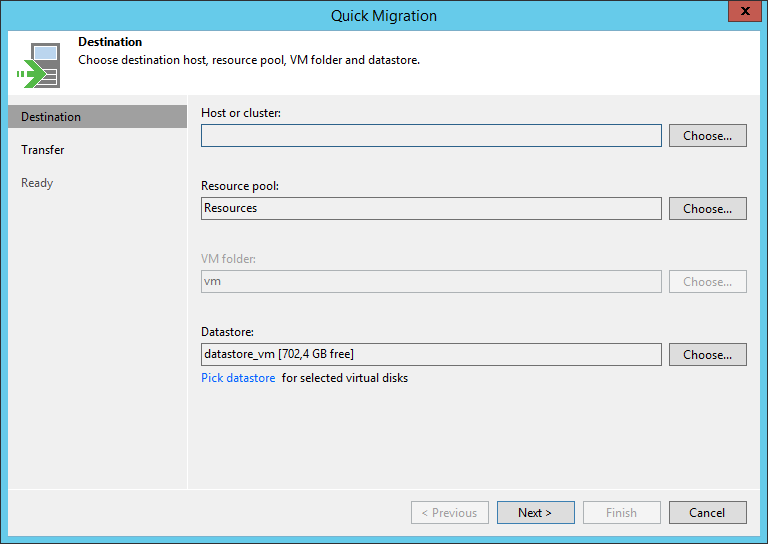
En allant sur Instant Recovery dans Veeam, je peux sélectionner mon dc03 et choisir Migrate to Production.
Une vérification des paramètres s’impose pour être sûr de finaliser la récupération au bon endroit, puis le déplacement sur l’environnement de production s’effectue.
Une fois l’opération terminée, je sélectionne l’option Stop Publishing sur dc03. Ainsi, il disparaît de VMware où il apparaissait en double : en tant que dc03 (fraîchement restauré) et dc03-xxxxx (la restauration de Veeam avant son déplacement sur l’environnement de production). Il ne reste donc plus que dc03.
Un petit tour dans les paramètres de la VM pour confirmer que tout est bien configuré : ne pas oublier de connecter la carte réseau avant de la démarrer.
Windows va s’initialiser puis redémarrer au bout de quelques minutes – c’est normal.
En réalité, Windows démarre en mode sans échec, se resynchronise avec les autres contrôleurs de domaine, réalise des mises à jour de fichiers de configuration avant de redémarrer. Une fois ce redémarrage terminé, l’OS est utilisable et répond aux requêtes AD comme si rien ne s’était passé. Tout le processus est entièrement automatique et géré par Veeam, qui lors de la sauvegarde, applique certains paramètres en détectant que la VM est un DC Windows.
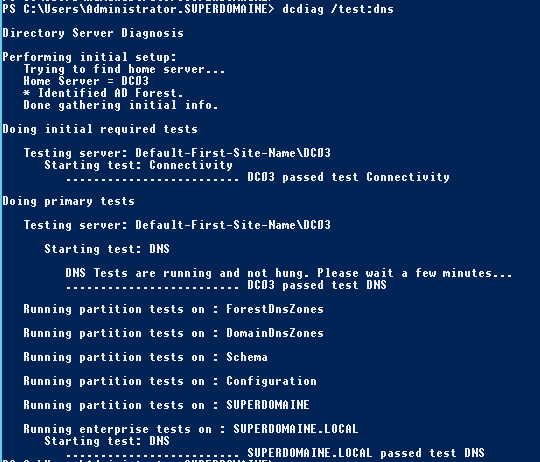
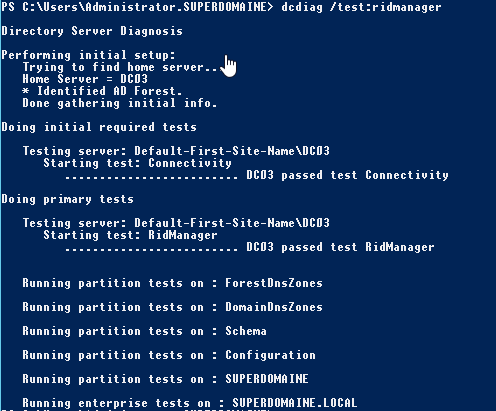
Il ne reste plus qu’à réaliser quelques tests grâce à dcdiag et repadmin :
Un dcdiag /a /i devrait tout de même renvoyer quelques erreurs systèmes qui ont été journalisées dans l’event viewer en fonction de la manière dont le DC a planté mais tous les autres tests devraient être en succès, pour peu qu’ils l’aient été pré-crash. D’autres tests comme la jonction de stations aux domaine doivent toujours fonctionner sans anicroche.
J’aime ça :
J’aime chargement…