Ce script prend un fichier CSV en entrée comprenant des noms de comptes AD afin de vérifier pour chacun s’il existe vraiment grâce à dsquery et réalise un export CSV de la liste générée.
$userlist = Import-CSV userlist.csv
$i = 0
$userexport = @()
foreach($user in $userlist){
if ((dsquery user -samid $user.Name) -eq $null) {
$user.name
$i++
$name=@{Name = $user.name}
$export = New-Object PSObject -Property $name
$userexport+=$export
}
}
Write-Host "Number of accounts not present in AD"$i" out of"($userlist.length)
$userexport | Export-CSV user-noexist.csv -NoTypeInformation
Pourquoi dsquery et non pas Get-AdUser ? Car ce dernier renvoie un message d’erreur si l’utilisateur n’existe pas et que le but du script est simplement de lister les users qui ne sont pas présents dans l’AD.
A noter qu’en fonction du titre de la « colonne » comportant les noms dans le fichier CSV, il sera nécessaire de modifier la requête -samid $user.Name en –samid $user.NomColonne.
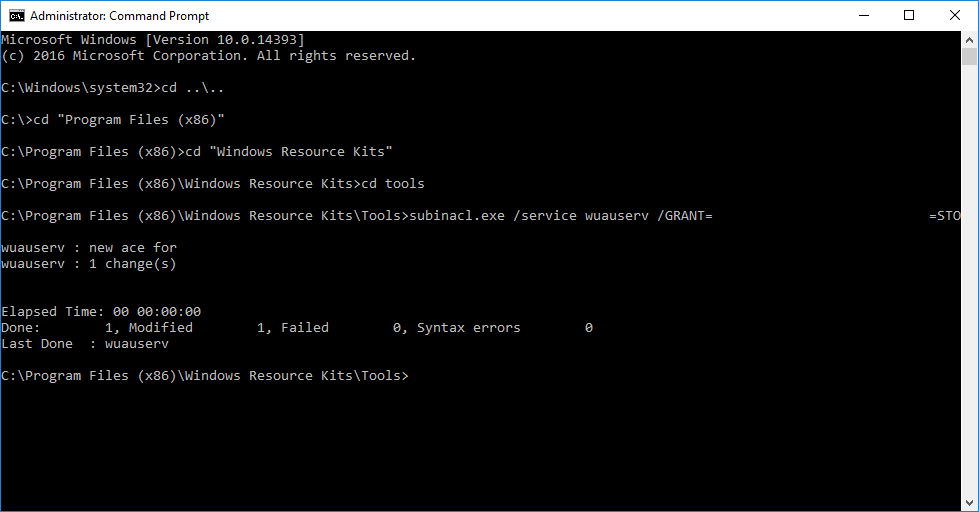
En recherchant un moyen d’accorder les droits de démarrage / arrêt sur un service particulier pour un compte d’utilisateur standard, je suis tombé sur cet article sur Serverfault. Le but était d’éviter d’accorder des privilèges d’administration à l’utilisateur en question.
Il existe donc un outil nommé SubInACL, qui fait partie du Windows Resource Kit (aux côtés de nombreux autres outils que je connaissais comme LockOutStatus). Cet outil qui s’exécute en ligne de commande permet de choisir précisément quels privilèges accorder sur un service pour un utilisateur, qu’il soit local ou du domaine.
J’ai testé cet outil sur un serveur de test en 2008 R2 et appliqué le fonctionnement sur un 2016 ; son exécution est très simple. Microsoft explique toute la syntaxe disponible à ce lien. Si je souhaite accorder à l’utilisateur dschrute le droit de voir l’état et de relancer le service NTP, je vais devoir envoyer cette instruction :
J’ai été confronté à un problème de manière aléatoire sur quelques machines virtuelles d’un cluster vSphere. Ce problème se traduisait par une perte de connectivité réseau : les machines virtuelles étaient incapables de joindre leur gateway et de communiquer avec d’autres machines du même VLAN. Une manière temporaire de rétablir la connectivité réseau était de réaliser un vMotion sur la machine virtuelle afin de la déplacer sur un autre hôte.
De nombreuses manipulations ont été tentées sur ces machines pour tenter de garder une connectivité durable : changement de type de carte réseau, création de nouvelle machine avec rattachement des disques virtuels, changement d’adresse MAC, etc. mais sans succès.
Les 2 hôtes vSphere formant le cluster ont chacun 4 interfaces physiques : 2 pour les machines virtuelles, une pour le management network et la dernière pour le vMotion. Sur ces deux dernières interfaces, seul un VLAN était déclaré côté switch physique.
En regardant du côté des vSwitch positionnés sur chaque hôte, il apparaissait qu’en fait les VLAN déclarés sur vSphere étaient poussés sur toutes les interfaces physiques (vmnic) du serveur. Cette configuration pouvait donc faire qu’une machine située sur le VLAN « PROD_CLIENT » tentait de communiquer sur les 2 interfaces qui n’avaient pas ce VLAN de déclaré côté switch physique.
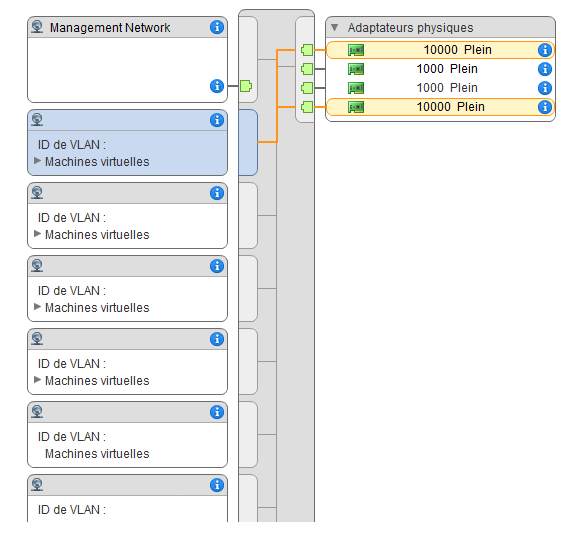
Explications : considérons un serveur avec 4 interfaces (vmnic0 à vmnic3) branchées sur les ports 1, 2, 3 et 4 d’un switch. Les ports 1 et 2 (branchés sur vmnic0 et vmnic1) donnent accès au VLAN « ADMIN » tandis que les ports 3 et 4 (branchés sur vmnic2 et vmnic3) donnent accès aux VLAN « PROD_CLIENT », « PROD_INTERNE », « RE7_CLI », « RE7_INT ». Côté vSphere, ces VLAN sont visibles et peuplés ; seulement ils doivent être configurés sur les bonnes interfaces. Si le VLAN « PROD_CLIENT » était accessible sur vmnic2 et vmnic3 puisqu’il est disponible sur les ports 3 et 4 du switch, il ne l’était pas sur les ports 1 (vmnic0) ni 2 (vmnic1). Or, ce VLAN était configuré sur ESXi pour utiliser les 4 interfaces physiques.
Sur cette capture, le VLAN est configuré pour être accessible sur tous les vmnic ; cependant côté switch physique cela n’est pas le cas puisque le VLAN est configuré sur les seuls ports 3 et 4 (vmnic2 et vmnic3).
Étant donné que ce VLAN utilisait des interfaces sur lesquelles il était injoignable côté switch physique, lorsque vSphere faisait passer le trafic réseau de la VM sur ces interfaces les machines devenaient de ce fait inaccessibles et incapables de joindre leur passerelle. Un redémarrage complet de la machine virtuelle (et non pas uniquement l’OS invité) pouvait résoudre le souci temporairement puisque vSphere réinscrit la carte réseau virtuelle sur une des interfaces sur lesquelles le VLAN en question était accessible (dans notre exemple, vmnic2 ou vmnic3). La même action de réinscription se faisait dans le cadre d’un déplacement d’hôte, puisque la VM passait sur un autre hôte physique, avec d’autres cartes physiques ; cependant le dysfonctionnement persistait puisque l’autre hôte du cluster était configuré de la même manière.
Afin de résoudre le dysfonctionnement, il a donc fallu déplacer les vmnic0 et vmnic1 dans les adaptateurs inutilisés pour les VLAN « PROD_CLIENT », « PROD_INTERNE », « RE7_CLI » et « RE7_INT ». Ainsi, le trafic des VM configurées sur ces réseaux passent désormais uniquement via vmnic2 et vmnic3 et le problème est résolu.
Sur cette capture, les VLAN sont bien configurés pour n’utiliser que les vmnic qui sont interfacés sur les ports du switch physique donnant accès aux VLAN en question.
J’avais déjà développé un script envoyant un mail si un datastore tombait sous un seuil défini dans le script d’espace libre. Aujourd’hui, voici une variante de ce script puisque celui-ci ne va détecter une espace disque trop faible mais une sur-allocation de celui-ci. En effet, avec les disques à provisionnement dynamique, il est possible de se retrouver en surcharge en créant de nouveaux disques virtuels positionnés sur ce même datastore sur lequel l’espace disque aura été jugé suffisant, en omettant de prendre en compte la croissance des disques déjà présents. Une capture d’écran peut permettre de comprendre le phénomène.
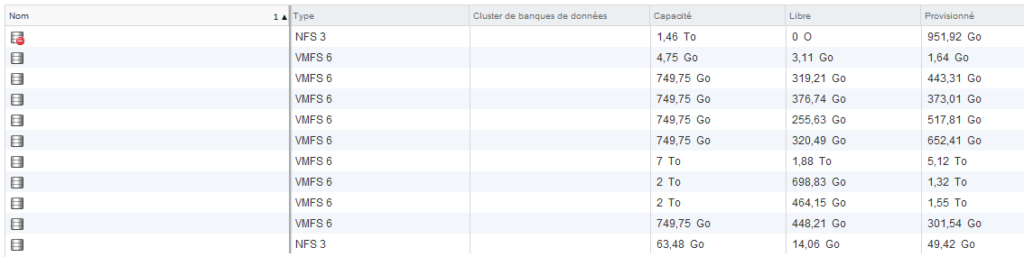
Cette capture d’écran montre bien les différences entre l’espace libre affiché et celui que l’on peut calculer en déduisant l’espace provisionné de la capacité maximale.
Sur cette capture, le sixième datastore affiche 320,49 Go de libre sur 749,75 Go : sur le papier, il est possible de créer une nouvelle VM puisque nous sommes en dessous du seuil d’occupation que l’on ne souhaite pas dépasser (généralement 80%). Seulement, 652 Go sur les 749 sont provisionnés. Cela signifie que si les disques virtuels viennent à atteindre leur taille maximale, nous serons en dessous des 20% d’espace libre. Pire, si la taille provisionnée est supérieure à la capacité, les disques virtuels seraient incapables de grossir et les VM pourraient planter.
Cela dit, il n’est pas forcément nécessaire de s’en tenir simplement à l’espace alloué et à la capacité maximale du datastore. Avec des machines bien dimensionnées et des données de capacity-planning, il est tout à fait possible d’exploiter chaque méga-octet du datastore sans perdre systématiquement au minimum 20% de l’espace de stockage.
Ce script liste donc tous les datastores qui ont un espace provisionné supérieur au seuil défini par rapport à la capacité maximale. Par défaut, ce seuil est de 80% (calculé par 1 – 0,20 dans le script). Il prend le nom du cluster en paramètre -Cluster. Dans une fenêtre PowerCli, on appellera le script ainsi si l’on souhaite analyser le cluster nommé PROD_PARIS :
Privacy & Cookies: This site uses cookies. By continuing to use this website, you agree to their use.
To find out more, including how to control cookies, see here:
Politique relative aux cookies