Je passe pas mal de temps à regarder les meilleures options pour coupler Google Drive à Plex, et je me suis heurté récemment à un problème par rapport à l’API de Google Drive en utilisant rClone. Lorsque Plex analyse les bibliothèques pour la première fois, il passe par rClone qui émet une requête à l’API. Cependant, lorsqu’on a énormément de médias (dans mon cas, 4,6 To), les requêtes se multiplient et le compte utilisé dépasse le quota ; quota remis à zéro toutes les 24 heures. Cela peut s’avérer problématique car Plex ne peut du coup indexer tout correctement en une fois. Ce souci est dû au fait que rClone ne garde pas en cache l’arborescence des fichiers, ce qui fait qu’il doit interroger Google en permanence, au lieu de simplement la télécharger une fois et s’y référer lors des accès, en faisant évidemment des mises à jour périodiquement ; comme si un livre n’avait pas de table des matières pour lister les chapitres. Bien que ce soit une évolution prévue dans la prochaine version de rClone (1.37), en attendant, j’ai préféré opter pour une autre solution afin de satisfaire également ma curiosité.
Au lieu d’utiliser donc rClone pour coupler mon Plex à Google Drive, je vais utiliser google-drive-ocamlfuse, que je vais abréger par la suite en GDO, qui remplit le même rôle mais qui ne fonctionne qu’avec Google Drive, là où rClone est nettement plus polyvalent.
Je pars du principe que vous êtes avec un compte utilisateur root ou en utilisateur standard ayant une élévation grâce à sudo en ce qui concerne les premières commandes. Mon serveur Plex fonctionne sur Debian Jessie mais l’installation est presque Plug’n’Play sur Ubuntu (ajout d’un repository au préalable, voir sur cette page).
1. Installation
Si l’application est disponible pour certaines distributions (Ubuntu, ArchLinux…), elle n’est pas disponible directement pour Debian. Il y a donc des manipulations à réaliser en plus. Ces manipulations ont été traduites directement depuis la page Wiki officielle du projet, je les ai quelque peu clarifiées en même temps.
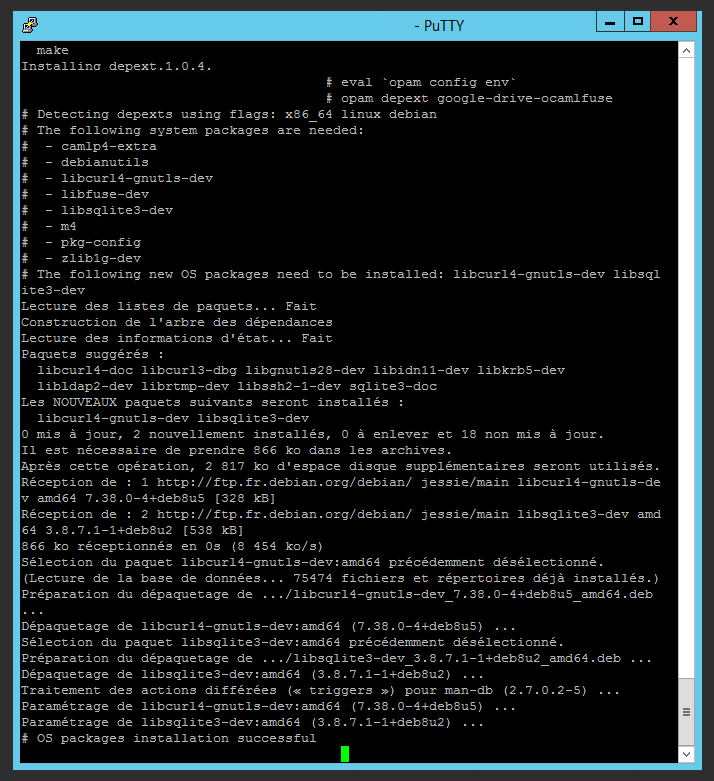
Dans un premier temps, il faut installer entre autres les paquets CAML, fuse, puis également make puisqu’on va devoir compiler depuis la source de l’application.
apt-get install opam ocaml make fuse camlp4-extra build-essential pkg-config
Ensuite, si le groupe fuse n’existe pas déjà sur le système, il faut le créer et ajouter le compte qui lancera l’application. Pour ma part, je me sers d’un compte générique tout simple et non de mon compte utilisateur.
groupadd <username> fuse
Ensuite, sur le répertoire de fuse, on va appliquer les bonnes autorisations afin que l’utilisateur qui va lancer google-drive-ocamlfuse puisse utiliser fuse :
chown <username> /dev/fuse
chmod 660 /dev/fuse
Attention : on ne manquera pas d’exécuter les instructions suivantes avec l’utilisateur qui exécutera GDO.
Puis, on installe ce qui est nécessaire au téléchargement et à la complication de google-drive-ocamlfuse (opam est un gestionnaire de paquets ocaml). Tout comme ce qui est indiqué dans la manipulation, j’ai laissé les options par défaut et cela fonctionne très bien.
opam init (option par défaut : N)
opam update
opam install depext
eval `opam config env`
opam depext google-drive-ocamlfuse (si des paquets système manquent, ils seront installés)
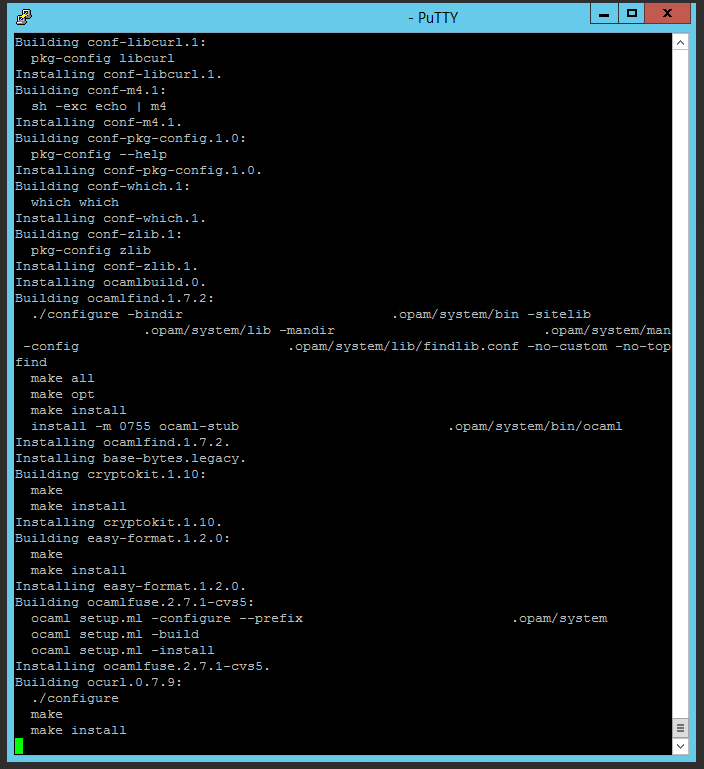
opam install google-drive-ocamlfuse (valider l’installation des paquets ocaml, le make du paquet ocamlnet est plutôt long, c’est normal)
Et voilà, GDO est installé et prêt à être lancé !
2. Premier lancement et autorisation
Si la machine sur laquelle est installé GDO possède un navigateur web, alors le premier lancement et l’authentification auprès du compte Google est aisée.
Sinon – ce qui a été mon cas –, il faut obtenir des identifiants développeurs auprès de Google (il existe le même type d’identifiant sur Amazon, par exemple) et les renseigner dans l’application via le terminal.
En se rendant sur cette page, on s’identifie à son compte Google, puis on crée un projet auquel on donne un nom sans intérêt, puis on active l’API Drive, comme sur la capture d’écran :
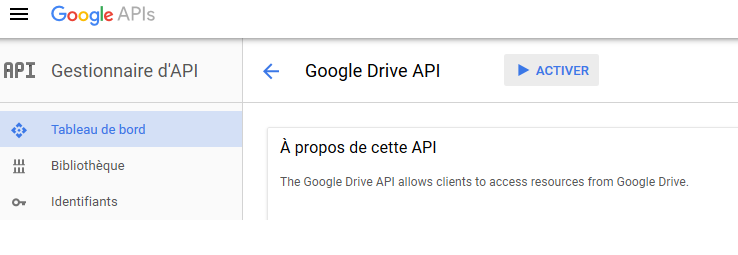 |
| Sur le site pour les développeurs de Google, il suffit d’aller sur le tableau de bord et d’activer l’API Google Drive |
Puis, on va procéder à la création des identifiants dont on a besoin. Naturellement, quelques paramètres sont à choisir, mais rien de très complexe, au final on ne donnera qu’un nom qui apparaîtra sur la page d’authentification un peu plus tard :
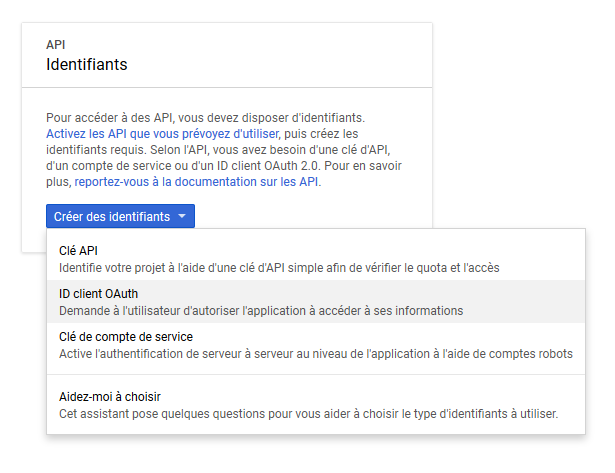 |
| On choisira ici « ID client OAuth » car notre application a besoin de pouvoir accéder au contenu du Drive |
A la fin de la création, deux identifiants sont communiqués : un ID Client et un Secret Client. Il convient de les noter par exemple dans un notepad car on va en avoir besoin juste après.
De retour sur le terminal, on exécute l’application, avec quelques paramètres :
google-drive-ocamlfuse -headless -id <client ID>.apps.googleusercontent.com -secret <secret ID>
Une URL apparaît alors dans le terminal. On copie-colle cette URL dans un navigateur web (donc, sur une autre machine), et il suffit de se connecter à son compte Google et à valider… notre propre application à s’authentifier. Une fois que l’autorisation est donnée, un token apparaît – qui n’est valide que 15 minutes, il me semble. C’est ce token qu’attend GDO pour finir d’être initialisé. Une fois cette manipulation terminée, l’application à accès au Drive.
Il reste un point à noter : en cas de redémarrage du système, on ne pourra plus relancer l’application ; elle apparaîtra comme introuvable. Il faudra relancer l’instruction suivante pour « réanimer » OPAM :
eval `opam config env`
Si l’on est amené à redémarrer fréquemment le serveur, il est tout à fait possible de placer cette instruction dans un script qui sera exécuté au démarrage par exemple.
3. Configuration
Avant tout lancement, il convient de passer en revue le fichier de configuration afin de modifier ce qui doit l’être pour un bon fonctionnement, et dans mon cas, éviter de générer trop de requêtes à l’API afin d’éviter d’être de nouveau bloqué.
Le fichier de configuration se trouve dans le répertoire de l’utilisateur qui a installé l’application – d’où l’intérêt de ne pas le faire en root, mais avec le compte qui exploitera le Drive. Un éditeur de texte comme nano fera le job pour y accéder :
cd #
nano .gdfuse/default/config
Je ne vais pas passer en revue toutes les options, cependant je vais parler de celles qui me paraissent les plus importantes ou intéressantes :
- metadata_cache_time : intervalle de temps entre deux requêtes à Google pour voir si le contenu a changé.
- read_only : comme son nom l’indique, cela permet de monter le Drive en lecteur seule. J’ai choisi cette option à true car je ne fais que de la lecture sur les fichiers.
- download_docs : cette option permet de choisir si l’on veut télécharger ce qui est stocké sur Google Documents. Je l’ai passé à false dans une optique de limiter le trafic et les appels à l’API.
- delete_forever_in_trash_folder : ce paramètre peut être dangereux si réglé sur true, car si les fichiers sont supprimés de la corbeille sur la machine, ils sont définitivement supprimés ; en étant sur false, l’application ne les supprime pas du Drive mais ne les affiche plus, il faut donc se connecter sur l’interface web pour les restaurer.
- shared_with_me : affiche ou non dans un répertoire /shared les fichiers partagés depuis d’autres Drive.
- max_download_speed, max_upload_speed : sans équivoque, permet de contrôler la bande passante.
- max_cache_size : en Mo, il s’agit du cache local concernant les fichiers accédés. Plex permettant de diffuser des films, j’ai augmenté le cache par défaut de 512 Mo à 5 Go.
Quelques options dans le cadre d’une utilisation avec Plex sont intéressantes :
stream_large_files : par défaut sur false, cette option permet de choisir si le serveur garde en cache le fichier qui dépasse la limite choisie dans le paramètre large_file_threshold_mb. Je l’ai laissée à false afin de récupérer le fichier une fois pour toutes et minimiser le trafic depuis et vers le Drive en permanence.
A noter que si cette option est sur true, il est possible de régler le nombre et la taille des tampons grâce à memory_buffer_size et read_ahead_buffers (par défaut, 3 tampons de 1 Mo). On peut également limiter la consommation en RAM de ceux-ci avec max_memory_cache_size. A noter que les valeurs à exprimer sont en octets (réels, c’est-à-dire 1048576 pour 1 Mo).
Si besoin, il est possible de trouver toute la documentation avec toutes les options possibles sur cette page. Globalement, les paramètres par défaut sont plutôt satisfaisants et nécessitent que peu de réglages manuels.
4. Montage
Maintenant que tout est prêt, on va pouvoir passer au montage du Drive et à l’accès aux fichiers.
google-drive-ocamlfuse /home/test/media/
Si tout s’est bien passé, le montage est instantané et il n’y a aucun retour, il suffit de naviguer dans le répertoire monté pour accéder aux fichiers. Afin de démonter le Drive, il suffit d’appeler fuse avec cette commande :
fusermount -u /home/test/media/
Et voilà, on a couplé – avec tout de même un peu plus de difficulté qu’avec rClone – Google Drive et un système GNU/Linux.
Page Github de google-drive-ocamlfuse
Page d’accueil des API Google
J’aime ça :
J’aime chargement…