Dans l’optique de repenser ma plateforme Cloud personnelle et de changer de serveur car désormais surdimensionné par rapport à mes besoins, j’ai essayé Scaleway, qui est une filiale d’Online, qui propose des serveurs virtuels et physiques à des prix plutôt intéressants avec une interface simple et mettant en avant la flexibilité et la rapidité.
L’offre de Scaleway est plutôt simple à comprendre :
- Les gamme Start, Pro et ARM sont basées sur des serveurs entièrement virtuels, cela signifie que les coeurs et RAM sont en partage avec d’autres utilisateurs sur le même serveur physique ;
- La gamme BareMetal représente les serveurs physiques dédiés.
J’ai testé la gamme Start avec 2 types de serveurs : le XS (1 core et 1 Go de RAM, pour 25 Go de disque) et M (4 cores, 4 Go de RAM et 100 Go de disque de base).
Au niveau des CPU, il s’agit d’Intel Atom C3955 ; peu performants en soi par rapport à ce que l’on peut trouver dans des serveurs mais suffisants pour bien des usages et permettant d’offrir un prix plancher puisque le XS coûte 2,40€ par mois TTC maximum, la facturation étant à l’heure, un serveur qui est détruit dans le mois ne coûte que les heures où il a fonctionné.
Concernant le stockage, c’est déjà un peu plus flou : il y a la notion de LSSD et de DSSD. Tous les disques chez Scaleway sont des SSD ; la différence entre le L et D SSD réside dans l’emplacement dudit stockage : le LSSD est en fait une allocation disque sur une baie de stockage en réseau, donc non-physiquement présente sur le serveur ou l’hyperviseur hébergeant votre machine, tandis que le DSSD est bel et bien un disque intégré au serveur. Ce qui est dommage, c’est que seul le plus gros serveur BareMetal comprend un DSSD ; pour le reste on est obligé de passer par la case disque réseau. Les performances sont cependant au rendez-vous, mais il faut garder à l’esprit qu’en fonction du noeud sur lequel notre serveur est installé cela peut fluctuer :
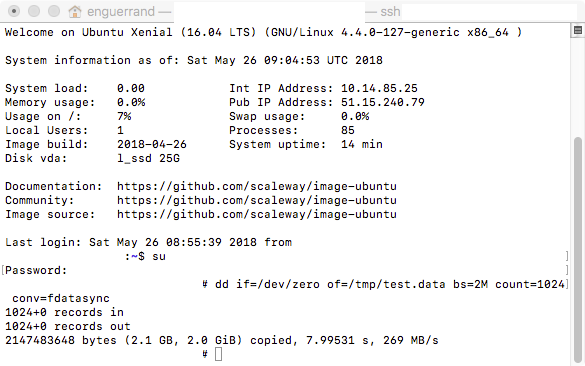
Seul le plus petit modèle héberge un LSSD de 25 Go, les autres serveurs offrent au minimum 50 Go de disque, extensibles par tranche de 50 Go, soit sur le même disque, soit en disque supplémentaires si l’on souhaite plusieurs points de montage. Dommage que la partition système ne soit pas extensible et soit figée à 50 Go. Par ailleurs, cela n’est pas précisé mais certains types de serveurs ont une limite de disques rattachables en nombre mais pas en taille ; si 1 To est le maximum de stockage pouvant être accolé à un serveur, au final sur un S on ne peut attacher qu’un disque, sur un M il n’est pas possible de rattacher un troisième disque, et ce qui est quelque peu idiot est qu’une fois un disque rattaché il n’est pas possible d’en augmenter sa taille (quelle raison, étant donné que ce ne sont que des allocations sur une baie ?)…
Le concept de flexibilité chez Scaleway est plutôt important car au final, le serveur n’est qu’un objet au même titre que les IP ou le stockage ou les images de déploiement ; on peut monter ou démonter nos LSSD sur n’importe quel serveur, supprimer un serveur sans perdre le stockage associé, etc. L’interface de gestion est plutôt claire et agréable à utiliser, même si potentiellement déroutante au départ pour qui ne parle pas anglais et/ou est néophyte. Quelque part le prix plancher des offres se paye par le support limité malgré une documentation relativement fournie par rapport aux services offerts.

La gestion d’un serveur est plutôt minimaliste mais a le bon goût d’offrir un accès console, permettant quand même de maniper au cas où le SSH est par terre ou bien que nous sommes connectés depuis une IP habituellement rejetée par SSH. On retrouve le nom du serveur, son emplacement géographique (Paris ou Amsterdam), son IP publique, son IP sur le réseau interne (qui change à chaque fois que vous éteignez ou rallumez votre serveur), et d’autres informations, y compris les disques. Par défaut, la connexion à un serveur se fait avec votre clé SSH renseignée dans votre compte.
La création d’un serveur est plutôt rapide, il doit se passer à tout casser 2 minutes entre le moment où l’on arrive sur la page de création et le moment où celui-ci est effectivement disponible :
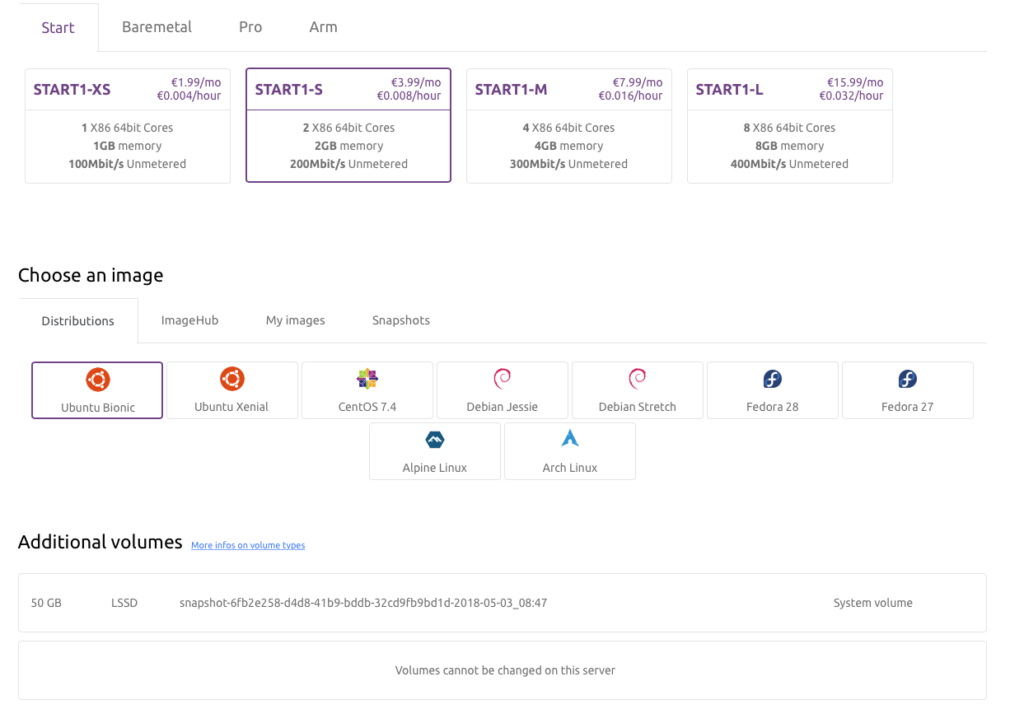
On choisit la taille du serveur désiré, la distribution ou application pré-installée (par exemple WordPress, PrestaShop, OpenVPN…) ou encore un déploiement par rapport à une image que vous avez créé vous-même (et non pas un ISO personnalisé…) et c’est parti. Le choix de distributions comprend l’essentiel et se limite au monde GNU/Linux ; la virtualisation se base sur KVM et il n’y a pas de Windows disponibles.
Au niveau réseau, pas de grosse surprise, sur 300 Mbps annoncés :

Lorsqu’on souhaite éteindre un serveur, le stockage est déplacé de la baie de stockage vers des « archives » et le serveur n’est plus accessible immédiatement. Ensuite, lorsqu’on souhaite le rallumer, le stockage redescend vers la baie et les coeurs sont de nouveau alloués ; cependant il arrive que le processus de « rallumage » de serveur prenne du temps car les ressources ne sont pas disponibles ; il convient donc de laisser allumé le serveur 24/7 à moins de vraiment vouloir tirer jusqu’au bout la notion de facturation à l’heure… et pour rendre le serveur indisponible on pourra plutôt couper la patte réseau afin qu’il ne communique plus via la console intégrée.
Actuellement, il ne me reste chez Scaleway que le miroir du blog (basé sur un lighttpd tout simple) ; j’y avais 3 autres serveurs que j’ai fini par bouger ailleurs sur un hyperviseur basé sur Proxmox. En effet, la puissance un peu légère des processeurs pour faire fonctionner Plex et quelques autres applications était problématique, et la gestion du stockage méritait d’être améliorée car en total décalage avec la flexibilité annoncée et plutôt réelle du reste des éléments du cloud. En l’état, Scaleway est une très bonne plateforme pour y monter des serveurs peu critiques ou pour se monter des labos de tests ou encore une petite infrastructure cloud légère ; en gros pour des besoins particuliers. Pour un usage professionnel ou plus sérieux, d’autres fournisseurs me semblent plus adaptés.
Si je devais faire un bilan de mon expérience chez Scaleway en deux semaines :
- Points forts : tarifs intéressants et à l’heure, rapidité de build d’un serveur, large panel de configurations matérielles, performances disques et réseau suffisantes dans une majorité de situations, flexibilité
- Points faibles : gestion du stockage, support limité en version de base, interface uniquement en anglais, disponibilité de l’infrastructure lors de la remise en route d’un serveur incertaine.