Pour un besoin ponctuel, j’ai eu à faire un recensement des disques locaux et de leur état sur de multiples machines distantes. J’ai donc réalisé un script Powershell permettant de les lister et d’obtenir d’autres informations et d’en faire un export CSV qui devient finalement exploitable sous Excel grâce à la conversion (onglet Données > Convertir).
Ce script utilise WMI, il est donc important que le service soit en fonctionnement sur les machines cibles et que le pare-feu autorise la communication. Si il s’agit du pare-feu Windows, cela est très facile dans les réglages de ce dernier :
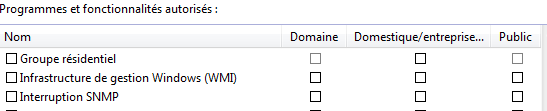 |
| Pour autoriser WMI, on coche les cases « Domaine » ou « Domestique/entreprise » en fonction de sa situation. |
A noter que le script commenté est également téléchargeable sur mon miroir de téléchargement.
Le script nécessite de placer simplement en paramètre le nom de la machine en question. On l’appellera par l’instruction suivante :
PS> .\win_listdisks.ps1 server.local
Param
([string]$Comp)
$output = @()
$DiskList = Get-WmiObject Win32_LogicalDisk -ComputerName $Comp
foreach ($Disk in $DiskList){
if ($Disk.DriveType -ne 3){continue}
$DiskLetter = $Disk.DeviceID
$DiskName = $Disk.VolumeName
$DiskSize = $Disk.Size
$DiskFS = $Disk.FreeSpace
$DiskSize = [long]$DiskSize/1073741824
$DiskFS = [long]$DiskFS/1073741824
$DiskPerc = ($DiskFS/$DiskSize)*100
echo "Disk $DiskLetter"
echo "Name: $DiskName"
echo "Size: $DiskSize"
echo "Free: $DiskFS"
echo "Percentage Free: $DiskPerc"
$DiskObj = New-Object PSCustomObject
$DiskObj | Add-Member -Type NoteProperty -Name 'DiskLetter' -Value $DiskLetter
$DiskObj | Add-Member -Type NoteProperty -Name 'DiskName' -Value $DiskName
$DiskObj | Add-Member -Type NoteProperty -Name 'DiskSize' -Value $DiskSize
$DiskObj | Add-Member -Type NoteProperty -Name 'DiskFS' -Value $DiskFS
$DiskObj | Add-Member -Type NoteProperty -Name 'DiskPerc' -Value $DiskPerc
$output+=$DiskObj
}
$output | Export-CSV disks-$comp.csv
Ensuite, dans Excel, en convertissant le CSV en tableau en choisissant la virgule comme élément délimitant les données, on obtient quelque chose de lisible :